
kube-scheduler实现原理
版本:b91146af51e273d0d35d614266d98b716ab2c861 (2018年4月1号于master分支)
补充知识:Kubernetes QoS
- **Guaranteed: ** 所有resource的limit和request都相等且不为0
- **Best-effort: ** 所有resource的limit和request都没有赋值
- **Burstable: ** 除了Guaranteed和Besteffort都属于Burstable
调度流程
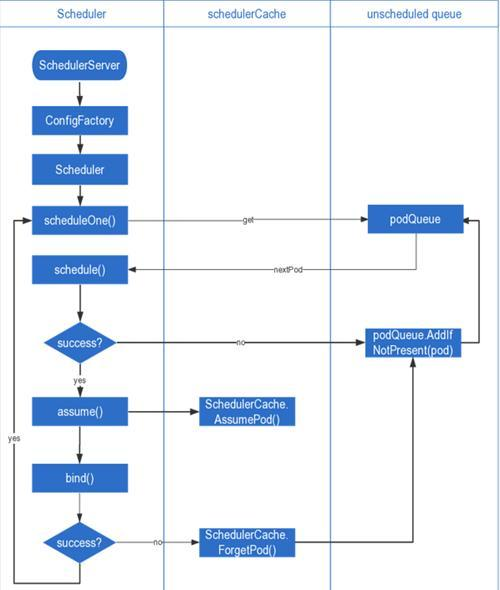
调度主要三个阶段:
- schedule()
通过predicate和priority选出最优节点。 - assume()
这个分为assumeAndBindVolumes和assume。
assumeAndBindVolumes会检测pv有没有准备好,没有就会让bindVolumesWorker异步bind volume并将pod重新加入调度队列,有的话就跳过。
assume将pod的调度信息缓存到本地内存schedulerCache中,因为bind是异步的,这样就不必等这个pod写入apiserver再调度下个pod了。 - bind()
异步进行,将pod的调度结果写入apiserver。
predicate
- NoVolumeZoneConflict:保证pod使用的pvc中的pv的声明区域包含node
- MaxEBSVolumeCount:防止被调度pod的EBS加上目标node上的EBS超过最大值(39)
- MaxGCEPDVolumeCount:防止被调度pod的GCEPD加上目标node上的GCEPD超过最大值(16)
- MaxAzureDiskVolumeCount:防止被调度pod的AzureDisk加上目标node上的AzureDisk超过最大值(16)
- MatcherInterPodAffinity:检测目标node上的pod是否与被调度的pod冲突,检测被调度的pod是否与目标节点上的pod冲突
- NoDiskConflict:分别判断pod的volume与node上每个pod的volume是否冲突,包括GCE、EBS、ISCSI、RBD
- GeneralPredicates:包含非关键性预选nocriticalPredicates(pod数量上限、cpu、memory、gpu等资源)和关键性预选EssentialPredicates(pod要求的node是否与目标node匹配、目标node上是否有pod要求的端口号、pod的node selector是否与目标node匹配)
- CheckNodeMemoryPressure:检查目标node上内存是否过载,只有Qos是Best-effort的pod才需要检查。
- CheckNodeDiskPressure:检查目标node上硬盘是否过载
- CheckNodeCondition:检查node是否ready、网络是否可用、是否OutOfDisk
- PodToleratesNodeTaints:检查pod的tolerations是否与node的taints的匹配
- CheckVolumeBinding:检查PVC和PV是否符合要求
priority
- SelectorSpreadPriority:属于相同service或者RC的pod在node上均匀分布,权重为1
map:node上有与被调度的pod相同selector的pod就score加1
reduce:MaxPriority(10)*[1/3 *(不同node最大score-当前node的score)/不同node最大score + 2/3 * (不同zone最大score-当前node的score)/不同zone最大score] - InterPodAffinityPriority:根据Affinity和Anti-Affinity进行加分减分,权重为1
- LeastRequestPriority:计算node上可分配的cpu和memory的score,权重为1
- BalancedResourceAllocation:计算node上cpu、memory、volume使用率的score,权重为1
- NodePreferAvoidPodsPriority:根据node上”scheduler.alpha.kubernetes.io/preferAvoidPods”的annotation计分,这个annotation会禁止ReplicationController或ReplicaSet的pod调度在其上面,默认权重为10000
- NodeAffinityPriority:根据Affinity计分,权重为1
map:根据pod的Affinity给node加分
reduce:归一化 - TaintTolerationPriority:根据toleration和taints是否匹配计分,权重为1
map:匹配toleration和taints
reduce:归一化 - ServiceSpreadingPriority:属于相同service的pod在node上均匀分布,map、reduce和SelectorSpreadPriority一样,权重为1
- EqualPriority:给所有节点提供相同的权重,权重为1
- ImageLocalityPriority:镜像及其相关依赖优先,map根据node上已有的镜像所需的包的大小计分,reduce为空,权重为1
- MostRequestedPriority:计算node上的cpu和memory的利用率的score,权重为1
Written on April 10, 2018